
API
QuickTabs - API
Lister les jeux de données
/d4c/api/datasets/2.0/search/
Description
Recherche des paquets satisfaisant à un critère de recherche donné.
Cette action accepte les paramètres de requête de recherche solr (détails ci-dessous) et renvoie un dictionnaire de résultats, y compris des jeux de données dictionnés qui correspondent aux critères de recherche, un compte de recherche et également des informations sur les facettes.
Dans le cas d'une utilisation sans paramètre de recherche, tous les Datasets sont restituées.
Paramètres Solr:
Pour un traitement plus approfondi de chaque paramètre, veuillez lire la documentation de Solr .
Cette action accepte un sous - ensemble de paramètres de requête de recherche de solr:
Paramètres
| q |
la requête solr. Optionnel. Par défaut: "*: *" |
|---|---|
| fq |
toutes les requêtes de filtre à appliquer. Remarque: + id_site: {ckan_site_id} est ajouté à cette chaîne avant l'exécution de la requête. |
| facet |
permet d'activer les résultats à facettes. Par défaut: vrai . |
| facet.mincount |
les nombres minimum pour les champs de facettes doivent être inclus dans les résultats. |
| facet.limit |
le nombre maximal de valeurs renvoyées par les champs de facette. Une valeur négative signifie illimitée. Cela peut être défini à l'échelle de l'instance avec l' option de configuration search.facets.limit . La valeur par défaut est 50. |
| sort |
tri des résultats de la recherche. Optionnel. Par défaut: 'pertinence asc, metadata_modified desc' . Conformément à la documentation de solr, il s'agit d'une chaîne de noms de champs et d'ordres de tri séparés par des virgules. |
| rows |
le nombre de lignes correspondantes à renvoyer. Il existe une limite stricte de 1 000 jeux de données par requête. |
| start |
le décalage dans le résultat complet pour l'endroit où l'ensemble des jeux de données renvoyés doit commencer. |
| facet.field |
les champs à facettes. Par défaut vide. Si vide, l'information de facette retournée est vide. |
| include_draft |
Si la valeur est True , les jeux de données de brouillon seront inclus dans les résultats. Un utilisateur ne recevra que ses propres jeux de données et un sysadmin sera renvoyé à tous les jeux de données de brouillon. Facultatif, la valeur par défaut est False . |
| include_private |
si True , les ensembles de données privés seront inclus dans les résultats. Seuls les ensembles de données privés provenant des organisations de l'utilisateur seront renvoyés et les administrateurs système recevront tous les ensembles de données privés. Facultatif, la valeur par défaut est False . |
| use_default_schema |
utilise le schéma de package par défaut au lieu d'un schéma personnalisé défini avec un plugin IDatasetForm (par défaut: False) . |
Les paramètres Solr avancés suivants sont également pris en charge. Notez que certains d'entre eux ne sont disponibles que sur des versions particulières de Solr. Voir la documentation dismac et edismax de Solr pour plus de détails à leur sujet:
qf , wt , bf , boost , cravate , defType , mm
Exemples:
q = ensembles de données flood contenant le mot flood , floods ou flooding fq = tags: ensemble de données economy avec le tag economy facet.field = ["tags"] facet.limit = 10 rows = 0 top 10 tags
Résultats:
Le résultat de cette action est un dict avec les clés suivantes:
| Type de retour: |
Un dictionnaire avec les clés suivantes |
|---|---|
| Paramètres: |
|
Un exemple de résultat :
{
'count': 2,
'résultats': [{<snip>}, {<snip>}],
'search_facets':
{
u'tags ':
{
'items ':
[
{
' count ': 1,
'display_name': u'tolstoy ',
'nom': u'tolstoy '
},
{
'count': 2,
'display_name': u'russian ',
'nom': u'russien '
}
]
}
}
}
Trouver l'identifiant du jeu de données (package_id) :
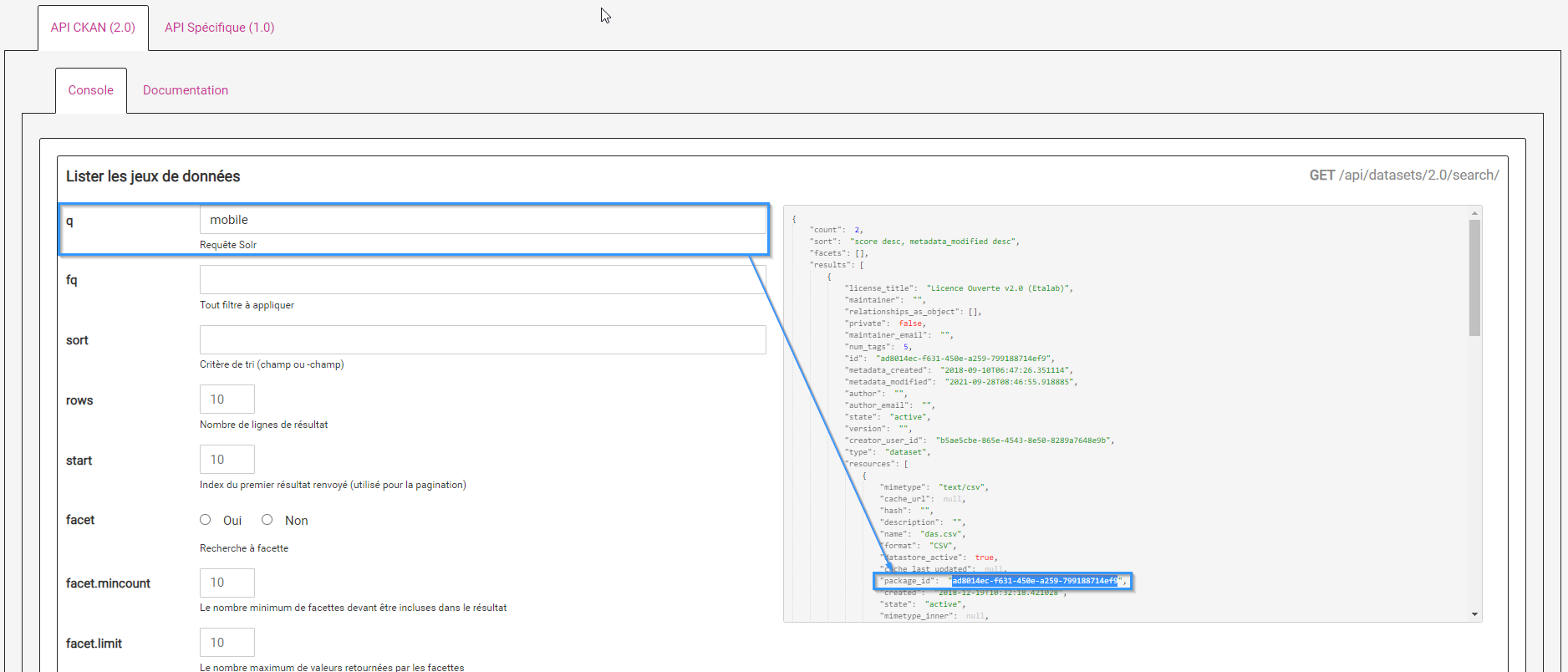
Consulter un jeu de données
/d4c/api/datasets/2.0/DATASETID/
Description
Renvoie les jeux de données (packages) d'un groupe.
Paramètres
| id |
l'identifiant ou le nom du groupe |
|---|---|
| limit |
le nombre maximal de jeux de données à renvoyer (facultatif) |
| Type de retour: |
liste de dictionnaires |
|---|
Trouver l'identifiant de la ressource à partir de l'identifiant d'un jeu de données (id dans resources ou resource_id)
Il faut regarder l'entrée "resource" correspondante au fichier CSV (format: CSV).
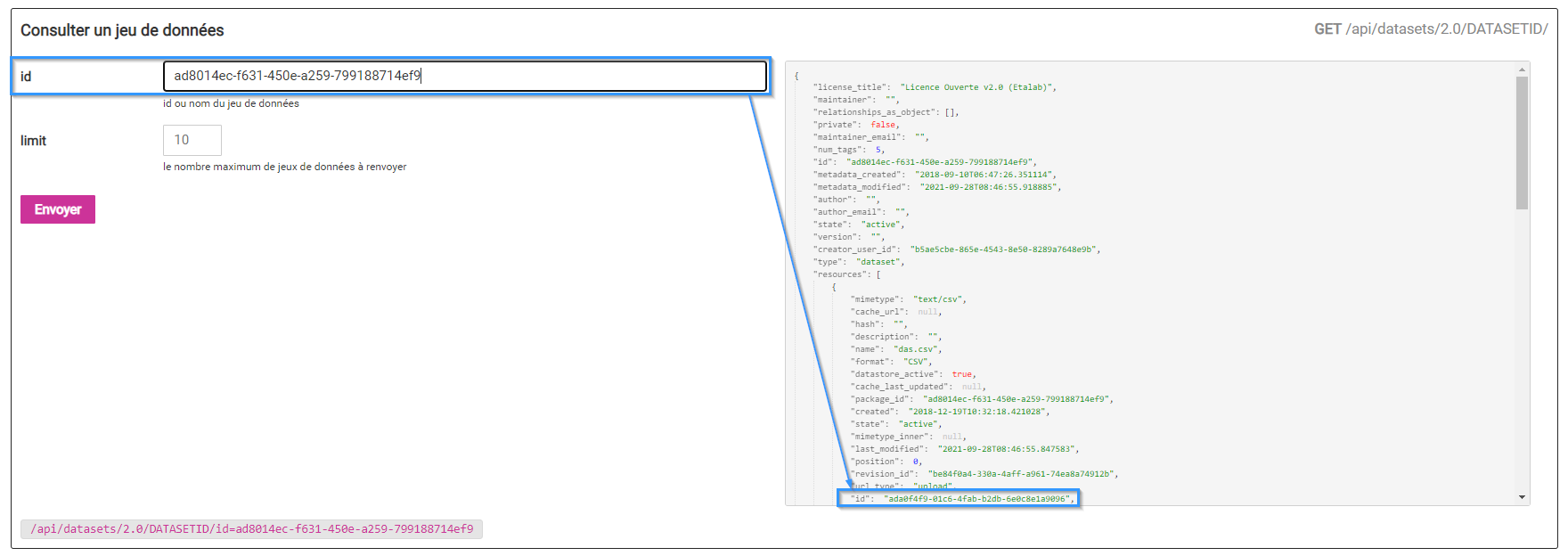
Recherche d'enregistrement
/d4c/api/records/2.0/search/
Description
Rechercher une ressource DataStore.
L'action datastore_search vous permet de rechercher des données dans une ressource. Les ressources DataStore appartenant à une ressource CKAN privée ne peuvent être lues par vous que si vous avez accès à la ressource CKAN et envoyez l'autorisation appropriée.
Mode de consommation
Ce service se consomme en GET. Le POST est également supporté mais non recommandé pour des raisons de standards.
Les formats de sortie supportés sont CSV (par défaut), JSON (ou JSONP en spécifiant un callback) et GeoJSON (callback également possible).
Paramètres
| resource_id |
id ou alias de la ressource à rechercher |
|---|---|
| filtres |
conditions de sélection à sélectionner, par exemple {"key1": "a", "key2": "b"} (facultatif) |
| q |
requête en texte intégral. Si c'est une chaîne, elle va chercher sur tous les champs de chaque ligne. Si c'est un dictionnaire comme {"key1": "a", "key2": "b"}, il va chercher sur chaque champ spécifique (optionnel) |
| distinct |
renvoie uniquement les lignes distinctes (facultatif, par défaut: false) |
| plain |
traiter comme une requête en texte brut (optionnel, par défaut: vrai) |
| language |
langue de la requête de texte intégral (facultatif, par défaut: anglais) |
| limit |
nombre maximum de lignes à renvoyer (facultatif, par défaut: 100) |
| offset |
décale ce nombre de lignes (facultatif) |
| fields |
champs à renvoyer (facultatif, par défaut: tous les champs dans l'ordre original) |
| sort |
noms de champs séparés par des virgules avec la commande par exemple: "fieldname1, fieldname2 desc" |
| include_total |
True pour retourner le nombre total d'enregistrements correspondants (facultatif, par défaut: true) |
| records_format |
le format de la valeur de retour d'enregistrements: 'objects' (valeur par défaut) liste de {fieldname1: value1, ...} dicts, liste 'lists' de listes [value1, value2, ...], ' Chaîne csv 'contenant des valeurs séparées par des virgules sans en-tête, chaîne' tsv 'contenant des valeurs séparées par des tabulations sans en-tête |
Définir l' indicateur brut sur false active l'intégralité du langage de requête de recherche de texte intégral PostgreSQL .
Une liste de toutes les ressources disponibles peut être trouvée sur l'alias _table_metadata .
Si vous devez télécharger la ressource complète, lisez Ressources de téléchargement .
Résultats:
Le résultat de cette action est un dictionnaire avec les clés suivantes:
| Type de retour: |
Un dictionnaire avec les clés suivantes |
|---|---|
| Paramètres: |
|
Consultation de données
/d4c/api/records/2.0/resource/
Description
Consulter des données d'une ressource.
Paramètres
| resource_id |
l'identifiant de la ressource |
|---|---|
| format |
format du résultat (facultatif) |
| refine |
permet d'affiner les résultats par facettes |
Exemples
refine = adm_lb_nom=BPT ensembles de données contenant la valeur BPT pour la facette adm_lb_nom
| Type de retour |
Liste de dictionnaires |
|---|
Téléchargement de la Documentation
Concepts généraux
Il existe un certain nombre de concepts au coeur de la plateforme :
| Dataset (ou Jeu de données) |
Un jeu de données est un regroupement logique de données (enregistrements): il est comparable plus simplement par exemple à une feuille Excel (dont chaque ligne serait un enregistrement) ou à une table de base de donnée (dont chaque entrée serait un enregistrement). Un jeu de données possède également des "metadatas", qui sont des attributs décrivant le jeu de données (par exemple sa date de première publication, son créateur, sa description ou ses mots clés). Un jeu de données contient également la liste des Fields (champs) qui constituent les enregistrements qu'il contient. |
|---|---|
| Record (ou Enregistrement) |
Un enregistrement est une donnée unitaire, comparable à une ligne d'un tableau Excel. Il est constitué de Fields (champs) avec les valeurs associés (comparable aux colonnes d'un tableau Excel). |
| Domaine |
Un Domaine est un espace regroupant des utilisateurs, des données (datasets), et les services permettant de créer, d'accéder et d'exploiter ces données (par exemple les API de recherche ou l'application Explore). Un Domaine peut exposer ses services (et ses données) à tous anonymement, ou les restreindre à ses propres utilisateurs. Un Domaine peut également choisir d'inclure dans ses services tous les jeux de données publics de la plateforme, ou de se restreindre à ses propres données. |
Services sur les jeu de données
Recherche (search)
https://data.anfr.fr/d4c/api/datasets/1.0/search/
Description
Ce service permet de consommer le catalogue de jeu de données par des fonctionnalités de recherche, telle la recherche dite "full-text", ou la navigation par Facettes. Il est ainsi possible de proposer aux utilisateurs des possibilités de recherche à la fois simples et intuitives (recherche textuelle "à la Google", mais également d'affiner facilement et précisément les résultats (facettes).
Dans le cas d'une utilisation sans paramètre de recherche, tous les jeu de données sont restituées.
Mode de consommation
Ce service se consomme en GET. Le POST est également supporté mais non recommandé pour des raisons de standards.
Paramètres
| q |
Requête textuelle "full-text". Par défaut, pas de requête, tous les résultats sont renvoyés. Documentation détaillée. |
|---|---|
| lang |
Langage de la requête utilisateur (paramètre |
| facet |
Active une Facette pour qu'elle soit incluse dans les résultats (voir Annexe pour la liste des Facettes disponibles); ce paramètre peut-être utilisé plusieurs fois pour activer plusieurs Facettes. Par défaut aucune Facette n'est activée. Ce paramètre n'est pas encore supporté.
|
| refine.<FACET> |
Limite les résultats à ceux inclus dans le chemin (path) spécifié pour cette Facette; peut-être utilisé plusieurs fois, pour une même Facette ou pour plusieurs Ce paramètre n'est pas encore supporté.
|
| exclude.<FACET> |
Exclut les résultats inclus dans le chemin (path) spécifié pour cette Facette; peut-être utilisé plusieurs fois, pour une même Facette ou pour plusieurs Ce paramètre n'est pas encore supporté.
|
| sort |
Trie les valeurs selon le champ spécifié (voir Annexe pour les champs disponibles au tri); par défaut le tri est descendant, mais si précédé d'un '-', le tri est ascendant.
|
| rows |
Nombre maximum de résultats à retourner. Par défaut, 10 résultats sont retournés. La valeur maximale de ce paramètre est |
| start |
Index du premier résultat à retourner (commence à 0); à combiner avec |
Récupération Unitaire (lookup)
https://data.anfr.fr/d4c/api/datasets/1.0/DATASETID/
Description
Ce service permet d'obtenir les informations sur un jeu de données donné.
Mode de consommation
Ce service se consomme en GET. Le POST est également supporté mais non recommandé pour des raisons de standards.
Les formats de sortie supportés sont JSON et JSONP (en spécifiant un callback).
Paramètres
| datasetid |
Dans l'URL, obligatoire : Identifiant du jeu de données, mentionné par exemple dans chaque résultat d'enregistrement
|
|---|
Services sur les enregistrements
Recherche (search)
https://data.anfr.fr/d4c/api/records/1.0/search/
Description
Ce service permet d'effectuer une recherche sur l'ensemble des données d'un jeu de données, à travers l'utilisation de fonctionnalités intuitives de recherche telles que la recherche textuelle et la recherche géographique; il permet également la navigation par Facettes pour offrir à l'utilisateur un moyen d'obtenir facilement et précisément les données souhaitées.
Dans le cas d'une utilisation sans paramètre de recherche, toutes les données du jeu de données sont restituées.
Mode de consommation
Ce service se consomme en GET. Le POST est également supporté mais non recommandé pour des raisons de standards.
Les formats de sortie supportés sont JSON (ou JSONP en spécifiant un callback) et GeoJSON (callback également possible).
Paramètres
| dataset |
Obligatoire : Identifiant du jeu de données(datasetid) où la recherche a lieu. |
|---|---|
| q |
Requête textuelle "full-text". Documentation détaillée. |
| lang |
Langage de la requête utilisateur (paramètre |
| geofilter.distance |
Restreint les résultats à une distance maximale (en mètres) donnée d'un point WGS84 donné :
|
| geofilter.polygon |
Restreint les résultats à une zone géographique donnée, déterminée par un polygone constitué de points WGS84 :
|
| facet |
Active une Facette pour qu'elle soit incluse dans les résultats (les Facettes disponibles sont indiquées au niveau de la défition du jeu de données); ce paramètre peut-être utilisé plusieurs fois pour activer plusieurs Facettes. Par défaut aucune Facette n'est activée.
|
| refine.<FACET> |
Limite les résultats à ceux inclus dans le chemin (path) spécifié pour cette Facette; peut-être utilisé plusieurs fois, pour une même Facette ou pour plusieurs
Exemple avec un filtre multiple :
|
| exclude.<FACET> |
Exclut les résultats inclus dans le chemin (path) spécifié pour cette Facette; peut-être utilisé plusieurs fois, pour une même Facette ou pour plusieurs. Ce paramètre n'est pas encore supporté.
|
| sort |
Trie les valeurs selon le champ numérique spécifié (les champs numériques sont indiqués au niveau de la définition du jeu de données); par défaut le tri est descendant, mais si précédé d'un '-', le tri est ascendant. Disponible uniquement si la recherche est effectuée sur un seul jeu de données.
|
| rows |
Nombre maximum de résultats à retourner. Par défaut, 10 résultats sont retournés. La valeur maximale de ce paramètre est |
| start |
Index du premier résultat à retourner (commence à 0); à combiner avec |
Annexes
Identifier un Jeu de Données (Dataset)
Vous cherchez des données précises pour construire une application mais ne savez pas encore dans quel jeu de données les trouver ?
Vous pouvez utiliser l'interface de recherche en choisissant API dans le menu en haut de page, et effectuer une recherche full-text sur l'ensemble des jeux de données et/ou jouer sur les filtres (affinages) tels que la source ou le nuage de mots-clés pour trouver le jeu de données qui contient les données qui vous intéressent. Une fois sur la page du jeu de données, il vous suffit de déplier les détails pour obtenir l'Identifiant que vous pourrez utiliser dans vos appels à l'API enregistrements (records).
Toute cette démarche est évidemment faisable intégralement via l'API, en utilisant l'API de recherche Datasets pour récupérer l'attribut "datasetid" du jeu de données qui vous intéresse.
Utilisation des Facettes
Une Facette est une catégorie à laquelle une entrée (un jeu de données ou un enregistrement (record)) peuvent appartenir avec une certaine valeur. Par exemple, pour une Facette "ville", un enregistrement pourrait appartenir à la valeur "Paris".
Les Facettes sont traditionnellement un outil d'aide à l'affinage de résultat dans les applications de recherche. On peut les utiliser pour rapidement restreindre ses résultats grâce à la vue d'ensemble de la répartition des résultats dans les valeurs des Facettes. Ainsi, pour une Facette "Dernière Modification", on pourra voir qu'il y a 240 résultats modifiés en 2012, 130 en 2011, et affiner ses résultats (affinages) sur 2011.
Récupération et Répartition
Par défaut, que ce soit pour les jeux de données ou les enregistrements, aucune Facette n'est activée. Pour cela, il faut activer les Facettes voulues par le paramètre "facet", en spécifiant le nom de la Facette. Dans le cas d'un jeu de données, les Facettes sont standard (tous les jeux de données ont les mêmes) et sont décrites dans une Annexe. Dans le cas de enregistrements, les Facettes disponibles sont définies au sein du jeu de données contenant les enregistrements :
...
"fields": [
...
{
"label": "VARIETE",
"type": "text",
"name": "variete",
"annotations": [
{
"name": "facet"
}
]
},
...
Les Facettes sont retournées à la fin des résultats retournés par la requête.
A chaque valeur correspond un name, qui est une valeur affichable dans une interface par exemple, et un path, qui permet d'effectuer un affinage ou une exclusion sur cette valeur. Les valeurs de Facettes sont sous forme hiérarchique, par exemple une année contient ses mois et ainsi de suite. Une valeur peut donc contenir d'autres valeurs.
Exemple pour les Facettes à l'intérieur d'une entrée :
"facet_groups": [
{
"name": "modified",
"facets": [
{
"name": "2012",
"path": "2012",
"facets": [
{
"name": "09",
"path": "2012/09",
"facets": [
{
"name": "11",
"path": "2012/09/11"
}
...
Dans le cas de la répartition des Facettes à la fin du résultat, chaque valeur contient également le nombre d'entrées contenues dans cette valeur (count), ainsi que son état (si elle est actuellement utilisée pour un affinage ou pour une exclusion). Le niveau de profondeur de hiérarchie pour une Facette est limité à 1, sauf si un affinage a lieu sur une valeur, auquel cas la profondeur descend jusqu'au niveau au dessous de la valeur filtrée.
"facet_groups": [
{
"name": "modified",
"count": 45,
"facets": [
{
"name": "2012",
"path": "2012",
"count": 24,
"state": "displayed"
},
...
Affinage
Il est possible de restreindre ses résultats (y compris pour une requête sans critère) en effectuant un affinage sur une valeur d'une Facette.
/d4c/api/datasets/1.0/search/?refine.modified=2011
Dans les résultats obtenus, seuls les jeux de données appartenant à la valeur 2011 pour la Facette "modified" sont retournés, c'est à dire les jeux de donnéesayant été modifiés en 2011. En réalité, un jeu de données sera dans une valeur correspondant au jour de sa dernière modification (2011 > 12 > 04 par exemple), mais puisque les valeurs sont hiérarchiques, elle appartient également au mois et à l'année.
Puisque l'affinage a eu lieu sur l'année, on observe que dans la répartition des Facettes à la fin des résultats, on récupère le niveau inférieur, le mois; également, l'année est marquée comme dans un état "refined" :
facet_groups: [{
name: "modified",
count: 20,
facets: [{
name: "2011",
path: "2011",
count: 20,
state: "refined",
facets: [{
name: "04",
path: "2011/04",
count: 7,
state: "displayed"
Langage de requête (paramètre q=)
Description
Le langage de requête peut être utilisé avec tous les points d'entrées d'API qui acceptent le paramètre q.
Il permet d'affiner la recherche de base et peut être utilisé en complément des facets.
| Recherche "plein texte" |
Permet de restreindre le résultat de la recherche sur les élément contenant les mots passés en paramètre Si la chaine de caractères est entre guillemets alors la recherche ne retourne que les résultats exacts
|
|---|---|
| Requête booléenne |
Le langage de requête supporte les opérateurs booléens : "AND", "OR" et "NOT" Les espaces dans les requêtes sont considérés comme des opérateurs “AND" L'utilisation des parenthèses permet de grouper les opérations Exemples :
|
| Requête sur les champs |
Le langage de requête permet de réaliser une requête sur un champ précis d'un jeu de données Les champs disponibles pour l'API Dataset sont définis plus haut. Les champs pour l'API enregistrements (records) dépendent du schéma du jeu de données que l'on souhaite interroger. La liste de ces champs peut être obtenue avec l'API Dataset Par exemple : Plusieurs types d'opérateurs peuvent être utilisés entre le nom du champ et la requête :
Le format de date peut être renseigné avec différent formats : simple (YYYY[[/mm]/dd]) ou ISO 8601 (YYYY-mm-DDTHH:MM:SS) Exemples :
|
| Fonctions du langage de requête |
Il est possible d'utiliser des fonctions dans le langage de requête. Il faut pour cela préfixer le nom de la fonction avec # Liste des fonctions disponibles :
|